

| Mathematics of Information Technology and Complex Systems |
| |
|||||
| |
|
||||
|
Research
Summary and project objectives
This research project deals with the mathematics of risk modeling and resource management, and the statistical analysis of financial data. The objective is to develop and implement new mathematical and statistical tools for pricing derivatives, hedging risk exposures and managing portfolios.
A. Characteristics function methods in finance Affine models are very popular in modeling financial time series as they allow for analytical calculation of prices of financial derivatives like treasury bonds and options. The main property of affine models is that the conditional cumulant function, defined as the logarithmic of the conditional characteristic function, is affine in the state variable. Consequently, an affine model is Markovian, like an autoregressive process, which is an empirical limitation. The main goal of the project is to generalize affine models by adding in the current conditional cumulant function the past conditional cumulant function. Hence, generalized affine models are non-Markovian, such as ARMA and GARCH processes, allowing one to disentangle the short term and long-run dynamics of the process. Importantly, the new model keeps the tractability of prices of financial derivatives. The first paper will study the statistical properties of the new model, derives its conditional and unconditional moments, as well as the conditional cumulant function of future aggregated values of the state variable which is critical for pricing financial derivatives. We will derive the analytical formulas of the term structure of interest rates and option prices. Different estimating methods will be considered (MLE, QML, GMM, and characteristic function based estimation methods). We plan to do three empirical applications. The first one will consider a no-arbitrage VARMA term structure model with macroeconomic variables and will show the empirical importance of the inclusion of the MA component. In the second application we will model jointly the high-frequency realized variance and the daily asset return in order to provide the term structure of risk measures such as the Value-at-Risk. The third application will use the model developed in the second application in order to price options theoretically and empirically. B. Regularization methods in finance We are interested in the estimation of financial models. The main difficulty lies in the fact that the underlying models assume continuous-time data, whereas the observations are discrete. As a result, the conditional likelihood of the observations is not available in closed form and therefore maximum likelihood estimation is not feasible. However in some cases, a closed-form expression of the characteristic function (CF) is available. As the information contained in the CF is the same as that contained in the likelihood, an estimator based on the CF will be as efficient as that based on the likelihood. The theory on using the CF for estimating diffusions has been developed Singleton (2001), Jiang and Knight (2002), Chacko and Viceira (2003), and more recently by Carrasco, Chernov, Florens, and Ghysels (2007). However, some technical issues remain and will be addressed here. In particular, we will develop a data-driven selection method for the tuning parameter that will permit us to reach the same efficiency as the maximum likelihood. An application on real financial data will complete this project. Integrated volatility is crucial for the accurate pricing of financial instruments. But a good estimator of the integrated volatility remains to be found. When financial data are observed at a high frequency, a way to estimate the integrated volatility is to use the realized volatility. However, the estimation precision is plagued by the presence of a noise, called microstructure noise. The noise importance increases with the frequency of the observations. Although the presence of such noise is commonly acknowledged, little is known on its properties. This project intends to fill this gap. To do so, we write a parametric model which is flexible enough to be realistic and we derive consistent estimators for the various parameters. We propose a battery of tests applied to the Dow Jones and show that the microstructure noise is autocorrelated and correlated with the asset price itself. This paper would complement recent work by Barndorff-Nielsen, Hansen, Lunde, and Shephard (2008). Since the seminal work of Markowitz (1952), mean-variance optimization has been considered the most rigorous way to perform portfolio selection. However, the implementation of this approach meets serious difficulties. In particular, the empirical covariance matrix is ill-conditioned when the number of assets is large. There have been various attempts to stabilize the inverse of the covariance matrix, including the shrinkage approach of Ledoit and Wolf (2003). However, in a recent article, DeMiguel, Garlappi and Uppal (2007) show via simulations that the out-of-sample performance of the mean-variance portfolio model and its extensions does not manage to outperform the na�ve portfolio where each asset receives an equal share. Our aim is to improve the current stabilization techniques of the covariance matrix by using regularization techniques borrowed from the statistical literature on inverse problems (see Carrasco, Florens and Renault, 2007). We will consider various types of regularizations including the LASSO, ridge and bridge regularizations. All these regularization techniques involve a smoothing parameter that needs to be selected. We will try to device a selection technique that will maximize the out-of-sample performance in terms of Sharpe ratio. C. Volatility measurement: multivariate and nonlinear methods High frequency returns are often used to compute risk measures. A popular example is the realized beta, which results from the regression of the high frequency returns on one asset on the high frequency returns of the market portfolio. Realized correlations and realized covariance are two other popular measures of risk that rely on high frequency returns. For these measures, inference is usually based on the first order asymptotic theory as derived by Barndorff-Nielsen and Shephard (henceforth BN-S) (2004). In particular, this paper provides a central limit theorem result for the realized covariance matrix over a fixed time interval assuming that the number of high frequency returns increases to infinity. The delta method implies that a central limit theorem also holds for smooth functions of the elements of the realized covariance, thus including the realized covariance, the realized correlation and the realized regression coefficients as special cases.
Although very convenient, the first order asymptotic approximation based on the standard normal distribution is not without problems. The simulation results of BN-S (2004) and Dovonon, Gon�alves and Meddahi (2008) for realized multivariate volatility measures show that the quality of this asymptotic approximation can be poor if sampling does not occur frequently enough. However, sparse sampling is often used as a caution against the effects of microstructure noise on these realized volatility measures.
D. Relationships between returns and volatility In this project, we propose to use realized variance and the bipower variation to analyze the relationship between expected returns and their variance. In paritcular, we will analyze this relationship using long-horizon regressions, common in the literature on the predictability of stock returns. These long-horizon regressions concentrate on the dynamics that are of interest to long-term investors such as the pension funds. Bandi and Perron (2008) consider regressions of the type:
The term on the left is the excess returns on the market portfolio between periods T and t+k. The term of right-hand side is the realized variance of the market portfolio between periods t-k and T. The use of longer horizons decreases the noise in the measurement of expected returns and gives more powerful tests (Campbell, 2001). The recent literature on long-run risks (Bansal and Yaron, 2004; Hansen, Heaton and Li, 2008; Bansal, Diitmar and Kiku, 2007; Maheu and McCurdy, 2007) suggests that agents value risks differently in the short and long runs and that the long-run risks are more important. In fact, Bandi and Perron (2008) find that variance predicts better long-run returns than short-run returns. The coefficients � in the regression above increase dramatically after 5 years.
Measurement errors caused by the presence of microstructure will have consequences on the estimation of the relationship between long-run expected returns and past realized variance. We know that, in general, measurement error on an explanatory variable leads to a bias towards 0 and non-convergence of the estimators. Characterizing microstructure noise in the estimation of the realized variance enables us to deduce the consequences for the estimation of the parameter of interest in the regression above. Moreover, this additional structure on the measurement error should enable us to trace the effects in time (in terms of various horizons) of this phenomenon. We will thus be able to quantify the impact of neglecting this source of risk on the choices of a long-run investor to look at the sensitivity of the results of Bandi and Perron to the presence of these microstructure noises. Moreover, the literature on the valuation of financial assets, especially the derivatives, shows the importance of accounting for the presence of jumps. We will thus use the bi-power variations suggested by Barndorff-Nielsen and Shephard (2002) which make it possible to separate the estimation of jumps from that of the variance. This will enable us to separate the impact on future long-run returns of jump and variance forecasts. We can also use realized variance obtained from high-frequency data to analyze the effect of ariance at various frequencies on returns. To accomplish this, we will use the heterogeneous ARCH (HARCH) model suggested by M�ller and al (1997) and Corsi (2004) and used recently by Andersen, Bollerslev and Diebold (2007). This model links excess returns to the variance measured at various horizons. It will thus entail regressing excess returns over a given period, say one month, on the variance over various periods, for example, one month, 6 months, one year and 5 years as in:
The estimated coefficients will measure, at various horizons, the impact of movements in variance on returns. Recent results of Maheu and McCurdy (2007) suggest that the long-run components, those which change most slowly, are most important. Finally, we consider extending this analysis to a cross-sectional context. That is we want to use realized variance as a conditioning variable in an asset-pricing model. In this model, risk aversion (and betas) would evolve over time according to a dynamics characterized by the realized variance of the market index. We will employ this conditional model on the 25 Fama and French (1996) portfolios sorted by size and value (the ratio of book value and market value). As in the two preceding cases, we expect that the power of this conditional model to reduce the pricing errors will be larger at longer horizons, 5 years and more. E. Factor models and identification problems in finance E.1 Identification-robust inference in factor-based and structural asset pricing models Arbitrage Pricing Theory based factor models [Ross (1976), Black (1972), Gibbons (1982), Barone-Adesi (1985), Shanken (1986), Zhou (1991, 1995), Campbell, Lo, and MacKinlay (1997, chapters 5 and 6), Velu and Zhou (1999) and Barone-Adesi, Gagliardini and Urga (2004a,b)] are a workhorse in empirical asset pricing to this day. Structural general equilibrium frameworks are also popular nowadays for fitting various financial models; these include multifactor pricing models when factors are observed with error, the conditional CAPM, and stochastic-discount-factor based models [MacKinlay and Richardson (1991), Jagannathan and Wang (1996), Harvey and Kirby (1996), Ferson and Harvey (1999), Ferson and Foertster (1994), Ferson (2003), Ferson and Siegel (2006)]. Such models are often empirically fragile because of statistical irregularities, and risks of spurious and misleading results that do not hold up to identification challenges are serious. Indeed, in such context, identification issues stem from the underlying theoretical structure, endogeneity and errors-in-variables, and nonlinear and reduced-rank restrictions; related problems arise in when the number of portfolios exceeds available sample size so variance-covariance estimates face singularity problems. We propose to develop inference procedures that are immune to such difficulties, i.e. that achieve error control whether the statistical framework is weakly or strongly identified [Dufour (2003); Stock, Wright and Yogo (2002)]. From a methodological perspective, we propose to develop a set of econometric tools that are useful for estimating and assessing the fit of a system of possibly structural equations. These tools would allow one to focus on a sub-model of choice yet are robust to many characteristics of the underlying full model, including full identification, missing instruments or error-in-variable problems. To circumvent identification problems, we propose set estimates for parameters of interest based on inverting: (i) Hotelling-type pivotal statistics, and (ii) multivariate extension of Anderson-Rubin type pivotal statistics. Hotelling's T� criterion is a widely used pivot in multivariate statistics and mostly serves for multivariate test purposes. Our proposed confidence sets promise much more informational content than such tests; we also propose simulation-based extensions for the case when the number of equations exceeds available sample size. As for the Anderson-Rubin statistic, while a large recent literature has documented its usefulness in univariate contexts, multi-equation extensions have not been directly addressed. From the empirical perspective, we propose to first consider various linear factor models and focus on factor selection and assessment methods. We aim to analyze various factor sets, including empirically motivated factors [(Fama and French (1995)] and alternative theoretically and empirically motivated factors [see Shanken and Weinstein (2006), Campbell and Vuolteenaho (2004) Bai and Ng (2006), and Ferson (2003)]. We also aim to document the effects of redundant factors and the number or considered securities or portfolios. Our proposed methods are appealing given that: (i) empirical work in the last decade in finance has relied considerably on Fama and French factors although studies are now coming out which question such models [see e.g. Shanken and Weinstein (2006) and the editor�s note by Ferson (2006)], (ii) traditional models which assume that returns move proportionally to the market have not fared well empirically [see Campbell (2000)], (iii) available related studies rely on regular asymptotics so there is no guarantee that results are non-spurious. Secondly, we propose to consider pricing models with conditioning information. Conditional asset pricing models motivated by financial market equilibrium principles are at the forefront of modern finance. Empirically, conditioning information takes the form of lagged financial variables that serve as instruments so equilibrium models can be confronted to the data. As emphasized by Ferson and Siegel (2006), and in view of our earlier work on conditional efficiency tests [see Beaulieu, Dufour and Khalaf (2007)], an important concern consists in integrating such instruments tractably and efficiently. Indeed, whereas using a large number of assets and more conditioning variables is conceptually appealing, degrees-of-freedom crunches along with numerical problems [such as inverting high-dimensional cross-correlation matrices] cause major difficulties in practice. In addition, a key issue in this context (which relates to Rolls�s critique (Roll (1977); see also the discussion in Ferson (2003) and the references therein) concerns testability when the full information set is not observed. In view of its statistical properties particularly on robustness to missing instruments, we believe that our proposed procedure holds great promise in this context. E.2 Noisy Betas: A New Approach to Estimating and Testing Cross-Sectional Asset Pricing Models The standard methodology in empirical tests of cross-sectional asset pricing models is based on a two-pass approach. The first step is to estimate the betas. The second step is to estimate a cross-sectional regression of expected returns on the betas. The coefficients on the betas are the estimated risk prices associated with the factors (and may reflect the underlying parameters of the asset pricing model, such as the coefficient of relative risk aversion). In this context, noisy betas are a well-known problem that can lead to biased estimates and poor test performance. More formally, this may be viewed as an errors-in-variables problem: an estimated beta (factor loading) is equal to the true beta plus noise (measurement error). On this issue, see, e.g., Shanken (1992, 1996), Kim (1995), Ferson (1995), Shanken and Weinstein (2006), and Shanken and Zhou (2007).
References Andersen, T., T. Bollerslev and F.X. Diebold, 2007. �Roughing it up: Including Jump Components in the Measurement, Modeling and Forecasting of Return Volatility,� Review of Economics and Statistics, 89, 4: 701-720.
List of publications
Beaulieu, M.-C., Dufour, J.-M. and Khalaf, L., 2007, ``Testing mean-variance efficiency in CAPM with possibly non-gaussian errors: an exact simulation-based approach'' (with Marie-Claude Beaulieu and Lynda Khalaf), Journal of Business and Economic Statistics, 25 (2007), 4, 398-410. www.jeanmariedufour.com
Networking As stated above, this project deals with the mathematical theory of risk modelling and resource management, and it includes both some research and technology transfer activities in relation with our industrial partners. The transfer activities take place in the context of the Centre interuniversitaire de recherche en analyse des organisations (CIRANO), where fundamental purpose consists precisely in establishing links and collaboration between nonacademia institution and university researchers. In the case of MITACS, this collaboration is done in the context of Finance group of CIRANO. The project partners are CIRANO (and its industrial affiliates in Finance, Banque Nationale du Canada, Hydro- Québec, Laurentian Bank of Canada, Desjardins Global Asset Management) and CIREQ-CRDE. The majority of the members of the team belong to CIRANO, an organization whose mission is to transfer knowledge to the industry. In the current project, the interaction with industry has taken various forms. First, regular working sessions are held with the CIRANO partners. Robert Normand, from Desjardins Globas Asset Management, is managing hedge funds and was recently presenting to several members of the team a project for a global macro fund that he would like to launch. The researchers provided a critical assessment of the procedures and several recommendations for improving the statistical soundness of the strategies. These exchanges occur quite frequently also with the other partners. Recently also, a portfolio management software was presented to Patrick Agin form Hydro-Québec and his team. The transfer of knowledge also takes the form of workshops and conferences, which are open to our industrial partners, researchers in the area and other MITACS groups [mainly in the Montréal area or working in Trading/Finance area (Haussmann)]. Several representatives from the industry (partners and othe r corporations) were present at the various workshops and conferences organized by the team members through CIRANO and the CRDE.
In this area, it is worthwhile to stress that we have organized up to now seven conferences on two major themes of
our research program, namely Asset Pricing and Portfolio Models and Statistical Models for Financial Time
Series. The first one was entitled “Intertemporal Asset Pricing Conference” (CIRANO, Montréal; October 22-23,
1999) and gathered some of the best experts of the field of mathematical asset pricing models in the world. The
second one was a thematic meeting of the Canadian Econometric Study Group on “Econometric Methods and
Financial Markets” (Université de Montréal; September 25-26, 1999) which also gathered some of the best experts
27
of the field. Both were of interest to academic researchers and our industrial partners and were well attended.
Besides we have organized two sessions on finance in the context of the last annual Meeting of the Société
canadienne de science économique, which was held jointly with the meeting of the Association des économistes
québécois (ASDEQ), a society of business economists, and we are running a highly successful series of Finance
seminars at CIRANO which is also of interest to our industrial partners. The third one was a Conference-
Workshop on Financial Mathematics and Econometrics (organized by J. Detemple, R. Garcia, E. Renault and N.
Touzi) with many leading researchers in the fields, which was held in Montreal (26-30 June 2001). Members of
other MITACS were present. The fourth one was a conference on Resampling Methods in Econometrics
(Université de Montréal, October 13-14, 2001, organized by J.-M. Dufour and B. Perron), a theme which is central
to the statistical part of our MITACS project. The conference attracted both econometricians, statisticians and
practitioners interested by applications and extensions of Monte Carlo tests and bootstrap techniques in
econometrics and finance. We will edit a special issue of the Journal of Econometrics based on the papers presented
at this conference. The fifth conference dealt with Simulation Based and Finite Sample Inference in Finance,
(Québec, May 2-3, 2003; organized by M.-C. Beaulieu, J.-M. Dufour, L. Kha laf and A. C. MacKinlay), which is a
major focus of our research project.. The sixth and seventh conferences consider were entitled Financial
Econometrics Conferences (Montréal, May 9-10 2003, May 4-5 2007, May 7-8 2004, organized by N. Meddahi) and now
becoming one of the major events of this field in the world. Given the success of these, several similar confereces took
place afterwards. These include: (1) 2 other Financial Econometrics Conferences (May 20-21, 2005; May 5-6, 2006); (2) a
conference on Forecasting in Macroeconomics and Finance (April 8-9, 2005); (3) a second conference on Simulation Based
and Finite Sample Inference in Finance (April 29-30, 2005); (3) a conference on Realized Volatility (April 22-23, 2006);
(4) the 2006 NBER-NSF Time\Series Conference (September 29-30, 2006); (5).
A conference Time Series analysis in econometrics and finance (December 8-9, 2006); (6) a conference on the Generalized Method
of Moments (November 16-17, 2007). Two other conferences organized by members of our group are now forthcoming: one on
forecasting in macroeconomics and finance (organized by J,-M. Dufour in association with IWH in Germany) and a
second one on Time Series to be held in Montreal (May 22-23, 2009).
Cooperation between the members of the team takes the form of numerous joint papers as well as conferences, workshops and seminars which are jointly organized. It has been effective and highly successful. |

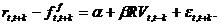
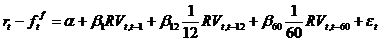
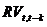 is market variance (as measured by the realized variance) over a period of k months. Dividing by k ensures that the regressors are in comparable units.
is market variance (as measured by the realized variance) over a period of k months. Dividing by k ensures that the regressors are in comparable units.